Fri Aug 28
[lecture notes]
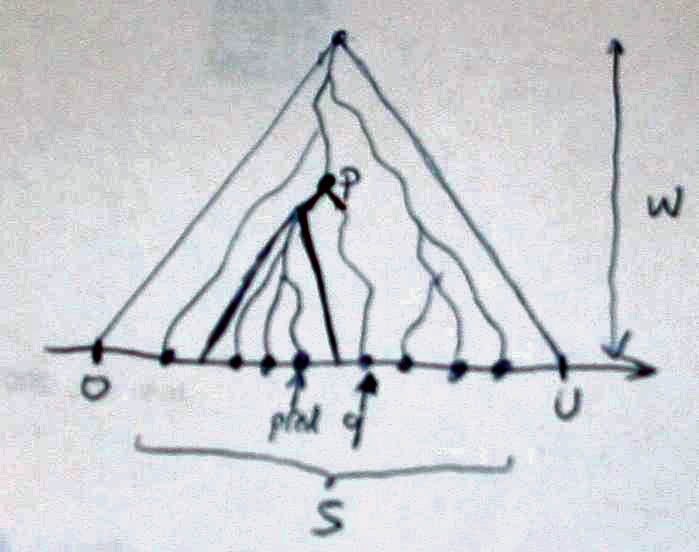
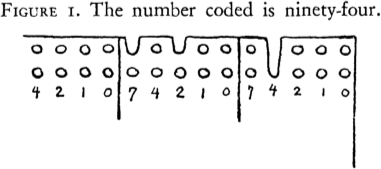
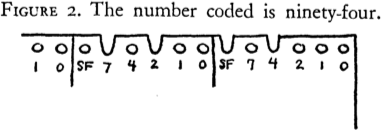
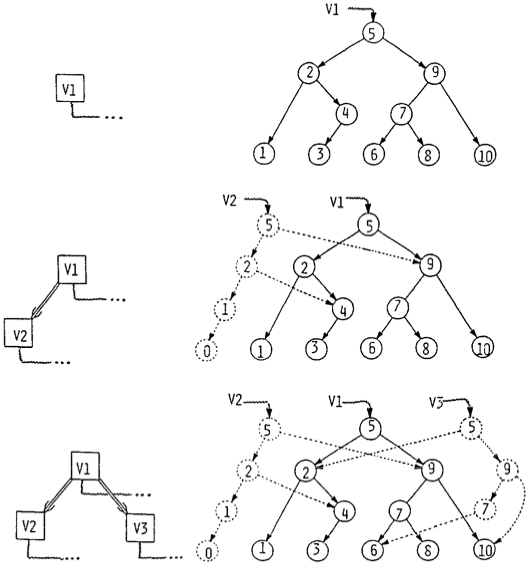
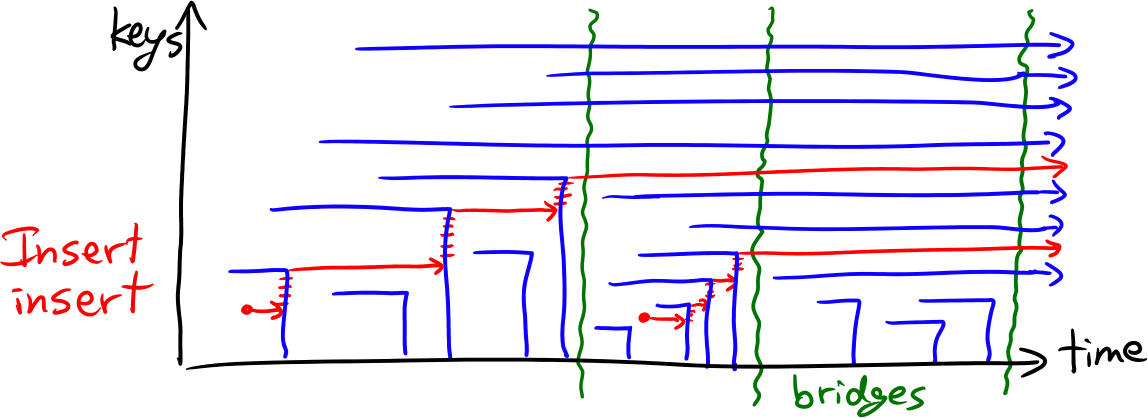
Decomposable searching problems: the Bentley-Saxe logarithmic method; local rebuilding; lazy deamortization; O(P(n)log n/n) worst-case insertion time; anti-data structures for invertible queries; weak deletions; (lazy) global rebuilding; O(P(n)log n/n) worst-case insertion time and O(P(n)/n + D(n)) worst-case deletion time.
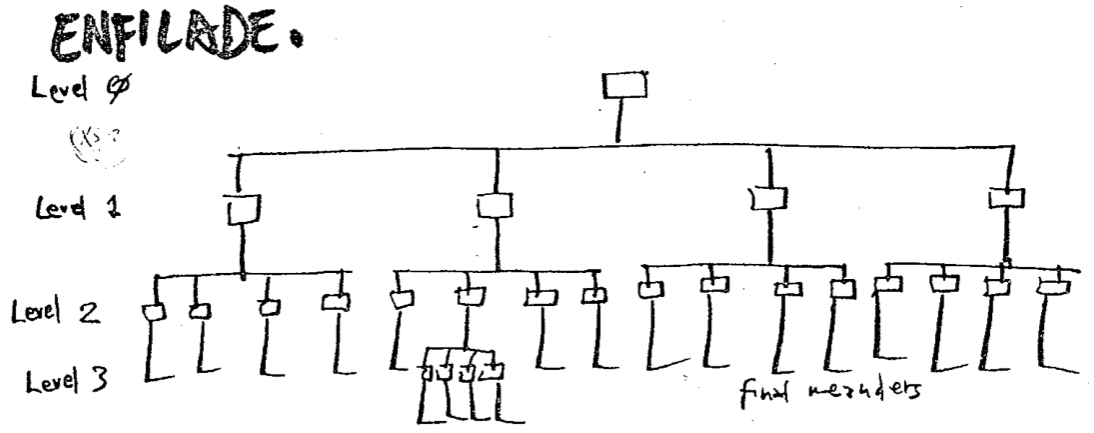
Lazy binary and lazy Fibonacci counters
after [Bentley Saxe 1980]
- Lars Arge and Jeffrey Scott Vitter. Optimal external memory interval management. SIAM J. Computing 32(6):1488–1508, 2003. [Among other results, describes weight-balanced B-trees, a prime example of a data structure that directly supports insertions and weak deletions.]
- Jon L. Bentley. Decomposable searching problems. Information Processing Letters 8:244–251, 1979.
- Jon L. Bentley. Multidimensional binary search trees used for associative searching. Communications of the ACM 18:509–517, 1975. [Introduces kd-trees, a prime example of a data structure that easily supports weak deletions, but not insertions or real deletions.]
- Jon L. Bentley and James B. Saxe*. Decomposable searching problems: 1. Static-to-dynamic transformations. J. Algorithms 1(4):301–358, 1980. [Introduces the logarithmic method for adding insertion to any static data structure for a decomposable search problem.]
- Michael J. Clancy* and Donald E. Knuth. A Programming and Problem-Solving Seminar. Stanford University Computer Science Department Report STAN-CS-77-606, April 1977. [One of the earliest examples of non-standard number systems being used to design efficient dynamic data structures—in this case, finger search trees.]
- Kurt Mehlhorn. Lower bounds on the efficiency of transforming static data structures into dynamic data structures. Mathematical Systems Theory 15:1–16, 1981.
- Kurt Mehlhorn. Data Structures and Algorithms III: Multi-dimensional Searching and Computational Geometry. EATCS Monographs, Springer, 1984. [Begins with a thorough overview of dynamization techniques for decomposable search problems. Still one of the best references for this material.]
- Kurt Mehlhorn and Mark H. Overmars*. Optimal dynamization of decomposable search problems. Information Processing Letters 12:93–98, 1981.
- Mark H. Overmars*. The Design of Dynamic Data Structures. Lecture Notes in Computer Science 156, Springer, 1983. [Mark's PhD thesis. Describes several families of methods for transforming static data structures into fully dynamic data structures, along with several geometric applications. Still one of the best references for this material.]
- Mark H. Overmars* and Jan van Leeuwen. Two general methods for dynamizing decomposable searching problems. Computing 26:155–166, 1981. [Describes a lazy version of Bentley-Saxe to modify data structures that support weak deletions and insertions, so that they support real deletions.]
- Mark H. Overmars* and Jan van Leeuwen. Worst-case optimal insertion and deletion methods for decomposable searching problems. Information Processing Letters 12(4):168–173, 1981. [Introduces the lazy local rebuilding technique for deamortizing Bentley-Saxe.]
- Himanshu Suri and Victor Vazquez. Combination Pizza Hut and Taco Bell. Shut Up, Dude, 2010. [They're at the Pizza Hut. They're at the Taco Bell. They're at the combination Pizza Hut and Taco Bell. Nearest neighbor searching is a decomposable search problem over an idempotent but non-inversive semigroup.]
Fri Sep 4
[lecture notes]
Scapegoat trees: O(log n) worst-case search and amortized update time using O(1) extra space
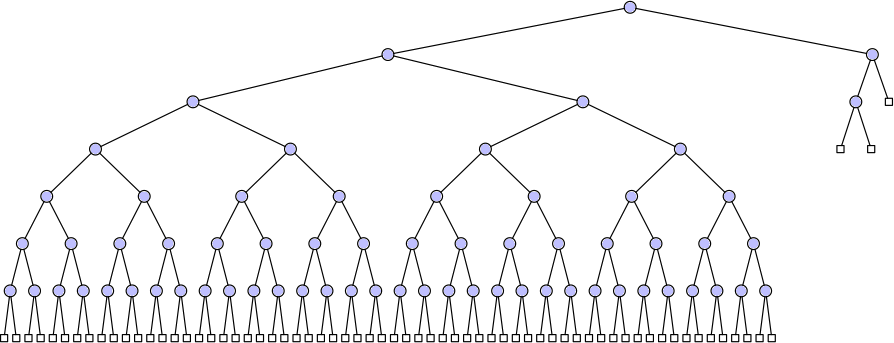
A well-balanced tree?
[Andersson, J. Alg. 1999]
- Arne Andersson*. Improving partial rebuilding by using simple balance criteria. Proc. Workshop on Algorithms and Data Structures, 393–402. Lecture Notes in Computer Science 382, Springer, 1989. [The first discovery of scapegoat trees.]
- Arne Andersson. General balanced trees. J. Algorithms 30:1–28, 1999. [The journal version of the previous paper.]
- Arne Andersson and Tony W. Lai*. Fast updating of well-balanced trees. Proc. 2nd Scandinavian Workshop on Algorithm Theory 111–121. Lecture Notes in Computer Science 447, Springer, 1990. [Scapegoat trees with depth lg n+c require only O(log²n/c) amortized time per insertion or deletion, for any constant c. The amortized update time can be reduced to O(log n/c) using a standard indirection trick: replace the leaves of the scapegoat tree with perfectly balanced subtrees of size Θ(log n).]
- Igal Galperin* and Ronald L. Rivest. Scapegoat trees. Proc. 4th th Annual ACM-SIAM Symposium on Discrete Algorithms, 165–174, 1993. [The second independent discovery of scapegoat trees and the origin of the name.]
Splay trees: rotations, roller-coasters and zig-zags, weighted amortized analysis, O(log n) amortized time, static optimality theorem, static and dynamic finger properties, working set property, dynamic optimality and other splay tree conjectures

A Self-Adjusting Search Tree
by Jorge Stolfi (1987)
- Ranjan Chaudhuri and Hartmut Höft. Splaying a search tree in preorder takes linear time. International J. Mathematics and Mathematical Sciences 14(3):545–551, 1991. Also appeared in SIGACT News 24(2):88–93, 1993.
- Richard Cole, Bud Mishra, Jeanette Schmidt, and Alan Siegel. On the dynamic finger conjecture for splay trees. Part I: Splay sorting log n-block sequences. SIAM J. Computing 30:1–43, 2000.
- Richard Cole. On the dynamic finger conjecture for splay trees. Part II: The proof. SIAM J. Computing 30:44–85, 2000.
- Amr Elmasry. On the sequential access theorem and deque conjecture for splay trees. Theoretical Computer Science 314(3):459–466, 2004. [Best upper bound known for the sequential access theorem: Accessing all n elements of a splay tree in increasing order requires at most 4.5n rotations.]
- Seth Pettie. Splay trees, Davenport-Schinzel sequences, and the deque conjecture. Proc. 19th Annual ACM-SIAM Symposium on Discrete Algorithms 1115–1124, 2008. [Proves that n deque operations on an n-node splay tree require at most O(n α*(n)) time, where α*(n) is the iterated inverse Ackermann function. The paper includes a thorough survey of other splay tree results, up to 2008.]
- Daniel D. Sleator and Robert E. Tarjan. Self-adjusting binary search trees. J. ACM 32:652-686, 1985. [HTML demo and C code] [The original splay tree paper.]
- Rajamani Sundar*. On the deque conjecture for the splay algorithm. Combinatorica 12(1):95–124, 1992. [Proves that n deque operations on an n-node splay tree require at most O(n α(n)) time, where α(n) is the inverse Ackermann function.]
- Robert E. Tarjan. Data Structures and Network Algorithms. CBMS-NSF Regional Conference Series in Applied Mathematics 44, SIAM, 1983. [Includes a chapter on splay trees. Yes, it took less time to publish an entire 130-page book than one 35-page journal paper.]
- Robert E. Tarjan. Sequential access in splay trees takes linear time. Combinatorica 5:367–378, 1985. [Established the sequential access theorem: Accessing all n elements of a splay tree in increasing order requires O(n) time.]
Wed Sep 9 [incomplete lecture notes]
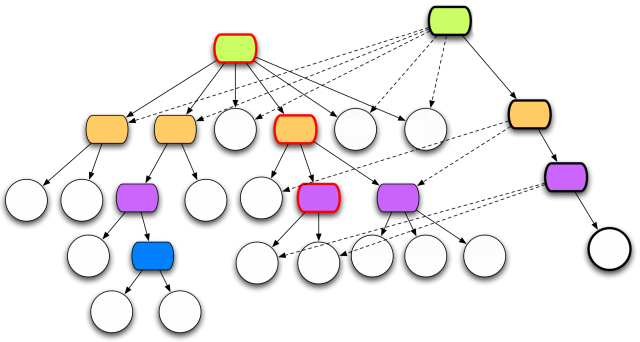
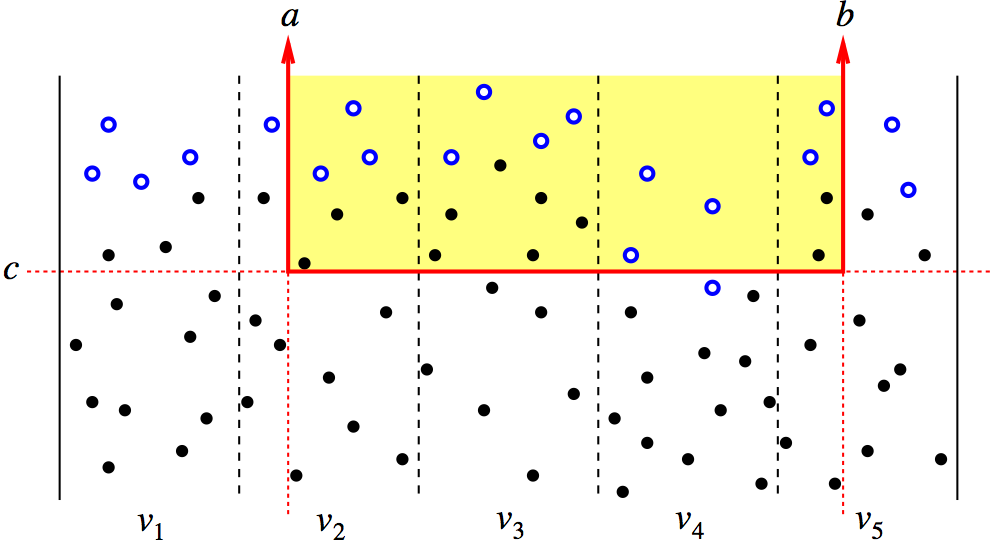
Lower bounds for dynamic binary search trees: arborally satisfied sets, independent rectangle lower bound, Wilber's interleave and alternation lower bounds, SIGNEDGREEDY lower bound, GREEDYFUTURE
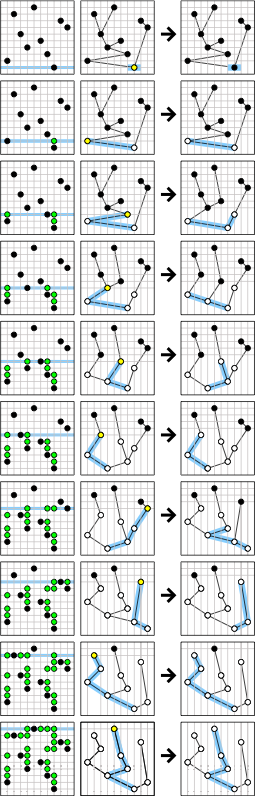
GREEDYFUTURE in action
[Demaine et al., SODA 2009]
- Parinya Chalermsook, Mayank Goswami, Laszlo Kozma, Kurt Mehlhorn, and Thatchaphol Saranurak. Self-Adjusting Binary Search Trees: What Makes Them Tick? Proc. 23rd European Symposium on Algorithms, 2015, to appear. arXiv:1503.03105.
- Erik D. Demaine, Dion Harmon*, John Iacono, Daniel Kane*, and Mihai Pătraşcu. The geometry of binary search trees. Proc. 20th Annual ACM-SIAM Symposium on Discrete Algorithms 496–505, 2009. [Introduces arborally satisfied sets, and proves their equivalence to dynamic binary search trees. See also Derryberry et al. 2005.]
- Jonathan Derryberry*, Daniel D. Sleator, and Chengwen Chris Wang*. A lower bound framework for binary search trees with rotations. Technical Report CMU-CS-05-187, Carnegie Mellon University, November 22, 2005. [A variant of the geometric view of dynamic binary search trees, developed independently from Demaine et al. 2009]
- George F. Georgakopoulos. Splay trees: a reweighting lemma and a proof of competitiveness vs. dynamic balanced trees. J. Algorithms 51:64–76, 2004. [Defines a class of so-called parametrically balanced dynamic binary search tree and proves that splay trees are O(1)-competitive within this class.]
- Dion Harmon*. New Bounds on Optimal Binary Search Trees. Ph.D. dissertation, Department of Mathematics, MIT, June 2006. [Describes the results in Demaine et al. 2009 in more detail, using slightly different terminology.]
- John Iacono. Key independent optimality. Algorithmica, 42:3–10, 2005.
- John Iacono. In pursuit of the dynamic optimality conjecture. Space-Efficient Data Structures, Streams, and Algorithms, 236–250, 2013. arXiv:1306.0207. [Surveys lower bound techniques and presents a dynamic BST that is optimal, assuming that an optimal dynamic BST exists at all.]
- Joan M. Lucas. Canonical forms for competitive binary search tree algorithms. Tech. Rep. DCS-TR-250, Rutgers University, 1988. [Introduces an offline dynamic binary search tree algorithm, called GREEDYFUTURE by Demaine et al.; see also Munro 2000.]
- J. Ian Munro. On the competitiveness of linear search. Proc. 8th Annual European Symposium on Algorithms 338–345. Lecture Notes in Computer Science 1879, Springer, 2000. [Independently describes the offline dynamic binary search tree algorithm called IAN (“Introduce As Necessary”) in Harmon's thesis and GREEDYFUTURE by Demaine et al.; see also Lucas 1988.]
- Robert E. Wilber*. Lower bounds for accessing binary search trees with rotations. SIAM J. Computing 18(1):56-67, 1989. [Proves two important lower bounds on the total access cost of dynamic binary search trees.]
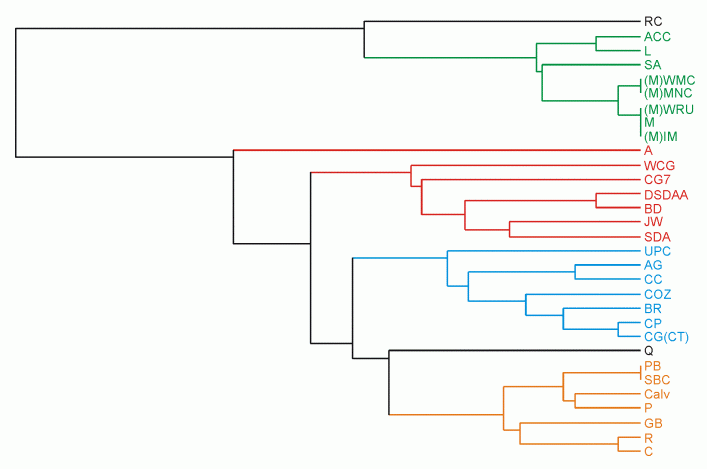
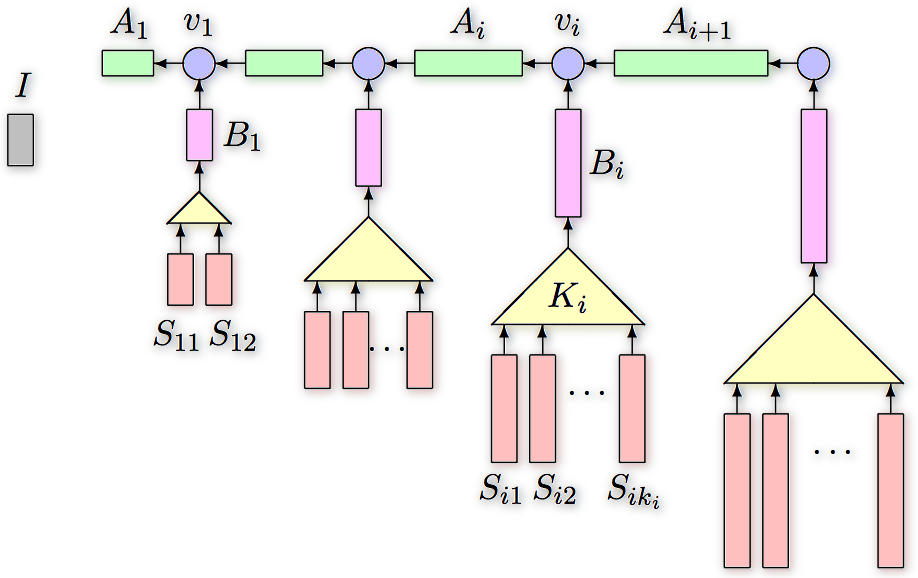
O(log log n)-competitive binary search trees: tango trees, multisplay trees, chain-splay trees, skip-splay trees, poketrees, zipper trees
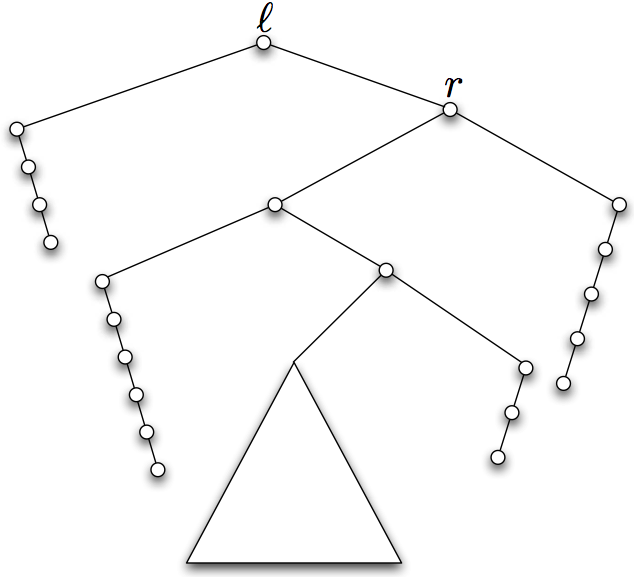
Representation of a preferred path in a zipper tree
[Bose et al., SODA 2008]
- Avrim Blum, Shuchi Chawla*, and Adam Kalai*. Static optimality and dynamic search-optimality in lists and trees. Algorithmica 36(3):249–260, 2003. [Describes a simple but computationally expensive dynamic binary search tree that is 14-competitive if the cost of rotations is ignored.]
- Prosenjit Bose, Karim Douïeb*, and Stefan Langerman. Dynamic optimality for skip lists and B-trees. Proc. 19th Annual ACM-SIAM Symposium on Discrete Algorithms 1106–1114, 2008. [Proves that among “weakly bounded” skip lists, the working set bound is a lower bound on the access time, and describes a “weakly bounded” deterministic self-adjusting skip list whose access time is within a constant factor of the working set bound.]
- Prosenjit Bose, Karim Douïeb, Vida Dujmović, and Rolf Fagerberg. An O(log log n)-competitive binary search tree with optimal worst-case access times. Proc. 12th Scandinavian Symposium and Workshops on Algorithm Theory, 38–49. Lecture Notes in Computer Science 6139, Springer, 2010. [Zipper trees, a O(log log n)-competitive dynamic binary search tree.]
- Parinya Chalermsook, Mayank Goswami, Laszlo Kozma, Kurt Mehlhorn, and Thatchaphol Saranurak. Self-Adjusting Binary Search Trees: What Makes Them Tick? Proc. 23rd European Symposium on Algorithms, 2015, to appear. arXiv:1503.03105.
- Erik D. Demaine, Dion Harmon*, John Iacono, and Mihai Pătraşcu. Dynamic optimality—almost. SIAM J. Computing 37(1):240–251, 2007. [Tango trees, the first O(log log n)-competitive dynamic binary search tree. Only competitive for searches, not for insertions or deletions.]
- Jonathan Derryberry*
and
Daniel D. Sleator.
Skip-splay: Toward achieving the unified bound in the BST model.
Proc. Workshop on Algorithms and Data Structures, 194–205.
Lecture Notes in Computer Science 5664, Springer, 2009.
[Another O(log log n)-competitive dynamic binary
search tree.]
- George F. Georgakopoulos. Chain-splay trees, or, how to achieve and prove log log n-competitiveness by splaying. Information Processing Letters 106(1):37–43, 2008. [Another O(log log n)-competitive dynamic binary search tree, based on splaying.]
- John Iacono. Alternatives to splay trees with O(log n) worst-case access times. Proc. 12th Annual ACM-SIAM Symposium on Discrete Algorithms, 516–522. [Defines the unified bound, and describes a dynamic dictionary (but not a binary search tree) that satisfies it.]
- Jussi Kujala* and Tapio Elomaa. Poketree: A dynamically competitive data structure with good worst-case performance. Proc. 17th International Symposium on Algorithms and Computation, 277–288. Lecture Notes in Computer Science 4288, Springer, 2006. [A O(log log n)-competitive dynamic data structure with O(log n) worst-case access time, but strictly speaking not a dynamic binary search tree.]
- Chengwen Chris Wang*. Jonathan Derryberry*, and Daniel D. Sleator. O(log log n)-competitive binary search trees. Proc. 17th Annual ACM-SIAM Symposium on Discrete Algorithms, 374-383, 2006. [Multisplay trees, the first O(log log n)-competitive dynamic binary search tree that competitively supports insertions and deletions.]
- Chengwen Chris Wang*. Multi-Splay Trees. Ph.D. dissertation, Department of Computer Science, Carnegie Mellon University, July 2006.
Wed Sep 16
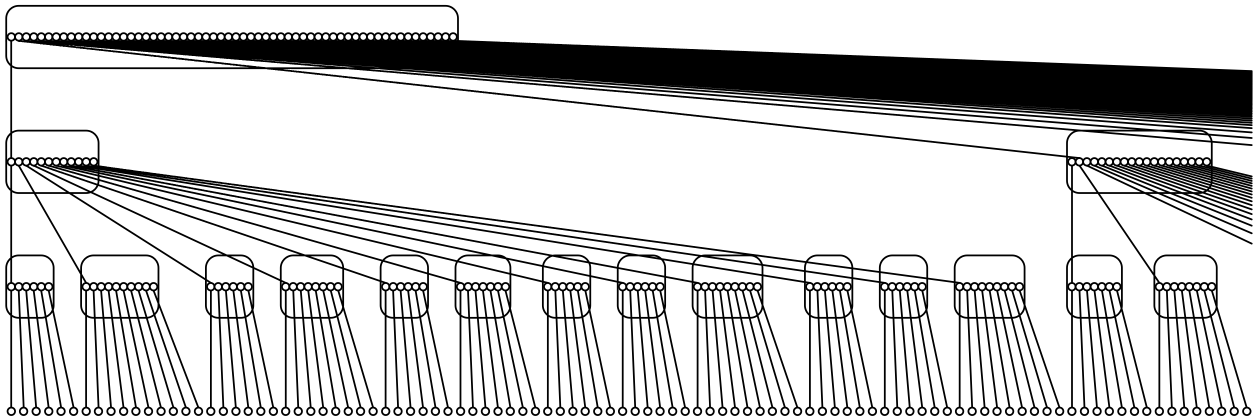
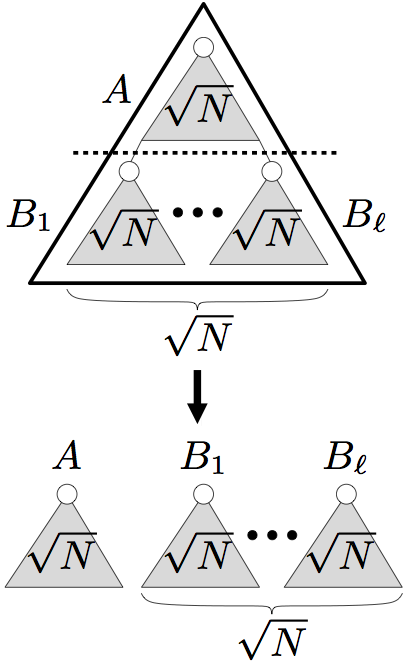
Dynamic forest maintenance: Link-cut trees; CUT, JOIN, and FINDROOT in O(log n) amortized time; path queries and updates in O(log n) amortized time via lazy propagation; Euler-tour trees; subtree queries and updates in O(log n) amortized time; sketches of topology trees, top trees, rake-compress trees, and self-adjusting top trees.
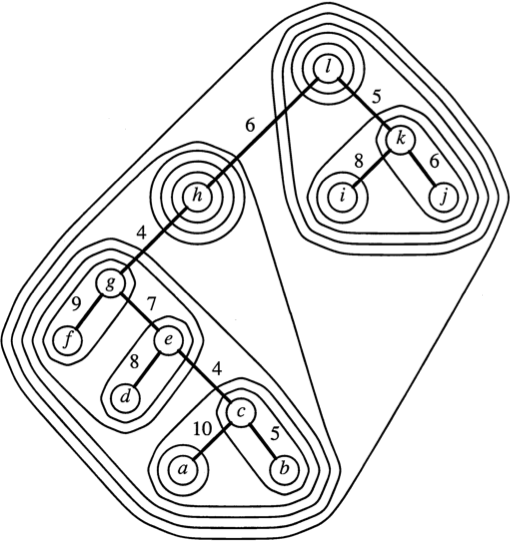
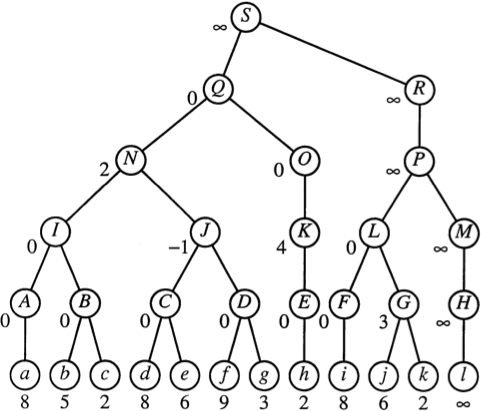
A multilevel partition of an edge-weighted binary tree, and the resulting topology tree.
[Frederickson 1997]
- Umut A. Acar*, Guy E. Blelloch, Robert Harper, Jorge L. Vittes*, and Shan Leung Maverick Woo*. Dynamizing static algorithms, with applications to dynamic trees and history independence. Proc. 15th Annual ACM-SIAM Symposium on Discrete Algorithms, 531–540, 2004. [Rake-compress trees.]
- Stephen Alstrup, Jacob Holm*, Kristian de Lichtenberg*, and Mikkel Thorup. Maintaining information in fully dynamic trees with top trees. ACM Transactions on Algorithms 1(2):243–264, 2005.
- David Eisenstadt. dtree: Dynamic trees à la carte. Last revised May 2014. Last accessed September 2015. [A C++ implementation of Sleator-Tarjan link-cut trees with (optional) support for subtree operations.]
- David Eisenstadt. mississippi: Multiple-source shortest paths and betweenness centrality in planar graphs. Last revised April 2014. Last accessed September 2015. [Includes a lightweight 80-line C implementation of Sleator-Tarjan link-cut trees.]
- Greg Frederickson. Data structures for on-line updating of minimum spanning trees, with applications. SIAM J. Computing 14:781–798, 1985. [Topology trees.]
- Greg Frederickson. A data structure for dynamically maintaining rooted trees. J. Algorithms 24:37–65, 1997. [Directed topology trees.]
- Andrew V. Goldberg, Michael D. Grigoriadis, and Robert E. Tarjan. Use of dynamic trees in a network simplex algorithm for the maximum flow problem. Mathematical Programming 50(1–3):277–290, 1991. [Added subtree operations to link-cut trees.]
- Monika Rauch Henzinger and Valerie King. Randomized fully dynamic graph algorithms with polylogarithmic time per operation. J. ACM 46:502–516, 1999. [Euler-tour trees; see also Tarjan 1997.]
- Gary L. Miller and John H. Reif. Parallel tree contraction and its application. Proc. 26th Annual IEEE Symposium on Foundations of Computer Science, 478–489, 1985. [Introduces the rake and compress operations in the context of parallel algorithms.]
- Gary L. Miller and John H. Reif. Parallel tree contraction part 1: Fundamentals. Randomness and Computation, 47–72. Silvio Micali, editor. Advances in Computing Research 5, JAI Press, 1989. [Full version of the previous paper.]
- Daniel D. Sleator* and Robert E. Tarjan. A data structure for dynamic trees. J. Computer and System Sciences 26:362–391, 1983. [The original formulation of link-cut trees via biased trees, with O(log n) worst-case operation time. Uses dynamic trees to obtain the first maximum-flow algorithm that runs in O(mn log n) time, based on blocking flows.]
- Robert E. Tarjan. Data Structures and Network Algorithms. CBMS-NSF Regional Conference Series in Applied Mathematics 44, SIAM, 1983. [Includes a chapter on link-cut trees, reformulated to use splay trees.]
- Robert E. Tarjan. Efficiency of the primal network simplex algorithm for the minimum-cost circulation problem. Mathematics of Operations Research 16(2):272–291, 1991. [Added directed-path operations to link-cut trees.]
- Robert E. Tarjan. Dynamic trees as search trees via euler tours, applied to the network simplex algorithm. Mathematical Programming 78(2):169–177, 1997. [Euler-tour trees; see also Henzinger and King 1999.]
- Robert E. Tarjan and Uzi Vishkin. An efficient parallel biconnectivity algorithm. SIAM J. Computing 14(4):862—874, 1985. [Introduces the Euler tour technique in the context of parallel algorithms.]
- Robert E. Tarjan and Renato Werneck*. Self-adjusting top trees. Proc. 16th Annual ACM-SIAM Symposium on Discrete Algorithms, 813–822, 2005.
- Robert E. Tarjan and Renato Werneck*. Dynamic trees in practice. J. Experimental Algorithmics 14, article 4.5, 2009. [Compares several dynamic forest structures, including Euler-tour trees, rake-compress trees, splay-based link-cut trees, top trees, self-adjusting top trees, and a brute-force link-cut tree with only parent pointers. For small graphs (up to a few thousand vertices), brute force wins. For larger graphs, link-cut trees win in applications with more links and cuts, there is no clear winner in applications with more queries. Really, ACM, what is this "Article 4.5" nonsense?]
Wed Sep 23
Applications of dynamic trees: Maximum flows via network simplex; parametric and multiple-source shortest paths; dynamic graph connectivity
An edge pivots into a planar shortest-path tree as the source node moves along an edge.
[Chambers Cabello Erickson 2007]
- Glencora Borradaile* and Philip Klein. An O(n log n) algorithm for maximum st-flow in a directed planar graph. J. ACM 56(2), article 9, 2009. [Does what it says on the tin.]
- Sergio Cabello, Erin W. Chambers*, and Jeff Erickson. Multiple source shortest paths in embedded graphs. SIAM Journal on Computing 42(4):1542–1571, 2013. [Generalizes Klein's planar multiple-source shortest path algorithm for planar graphs to graphs embedded on more general surfaces.]
- David Eppstein. Dynamic generators of topologically embedded graphs. Proc. 14th Annual ACM-SIAM Symposium on Discrete Algorithms 599–608, 2003. [Uses Thorup's dynamic connectivity data structure to dynamically maintain the generators of a fundamental group of a surface represented by a rotation system of a graph. Introduces tree-cotree decompositions for surface graphs. Those two sentences should make sense if you took my computational topology class last year.]
- Jeff Erickson. Maximum flows and parametric shortest paths in planar graphs. Proc. 21st Annual ACM-SIAM Symposium on Discrete Algorithms 794–804, 2010. [Expresses and reanalyzes Borradaile and Klein's planar maximum-flow algorithm in terms of parametric shortest paths.]
- Andrew V. Goldberg, Michael D. Grigoriadis, and Robert E. Tarjan. Use of dynamic trees in a network simplex algorithm for the maximum flow problem. Mathematical Programming 50(1–3):277–290, 1991. [Used dynamic trees to obtain another maximum-flow algorithm that runs in O(mn log n) time, based on network simplex, using a pivot rule of Goldfarb and Hao.]
- Monika Rauch Henzinger and Valerie King. Randomized fully dynamic graph algorithms with polylogarithmic time per operation. J. ACM 46:502–516, 1999. [Edge insertions and edge deletions in O(log3 n) amortized expected time, and connectivity queries in O(log n/log log n) time.]
- Jacob Holm*, Kristian de Lichtenberg*, Mikkel Thorup. Poly-logarithmic deterministic fully-dynamic algorithms for connectivity, minimum spanning tree, 2-edge, and biconnectivity. J. ACM 48(4):723-760, 2001. [Edge insertions and edge deletions in O(log2 n) time and connectivity queries in O(log n/log log n) time.]
- Raj D. Iyer, Jr.*, David Karger, Hariharan S. Rahul*, and Mikkel Thorup. An experimental study of polylogarithmic, fully dynamic, connectivity algorithms. J. Experimental Algorithmics 6, article 4, 2001.
- Philip Klein. Multiple-source shortest paths in planar graphs. Proc. 16th Annual ACM-SIAM Symposium on Discrete Algorithms 146–155, 2005. [Implicitly computes all shortest-path trees rooted on a single face of a planar graph in O(n log n) time. Stores both the shortest path tree and the dual cotree in dynamic tree data structures.]
- Robert E. Tarjan. Dynamic trees as search trees via euler tours, applied to the network simplex algorithm. Mathematical Programming 78(2):169–177, 1997. [Simplifies the O(mn log n)-time network-simplex maximum-flow algorithm of Goldberg, Grigoriadis, and Tarjan using Euler-tour trees.]
- Mikkel Thorup. Near-optimal fully-dynamic graph connectivity. Proc. 32nd Annual Acm Symposium on Theory of Computing, 343–350, 2000. [Edge insertions and edge deletions in O(log n (log log n)3) time and connectivity queries in O(log n/log log log n) time, almost matching the Ω(log n) lower bound.]
Lower bounds for dynamic connectivity: Cell probe model, prefix sums, reductions, time trees, non-deterministic encoding

Reducing dynamic prefix-sum to dynamic connectivity
[Demaine Pǎtraşcu 2006]
- Michael L. Fredman and Monika Rauch Henzinger. Lower bounds for fully dynamic connectivity problems in graphs. Algorithmica 22(3):351–362, 1998. [Among other results, observes an easy reduction from parity prefix sums to dynamic reachability. See also Miltersen et al. 1994.]
- Michael L. Fredman and
Michael E. Saks.
The cell probe complexity of dynamic data structures.
Proc. 21st ACM Symposium on Theory of Computing, 345–354, 1989.
[Introduces the chronogram technique for proving
cell=probe lower bounds. Proves an Ω(log n/log log n)
lower bound for dynamic parity prefix sum.]
- Peter Bro Miltersen. Cell probe complexity: A survey. Manuscript, 2000. Invited talk/paper at Advances in Data Structures, a pre-conference workshop of FSTTCS'99. [Powerpoint slides]
- Peter Bro Miltersen, Sairam Subramanian*, Jeffrey Scott Vitter, and Roberto Tamassia, Complexity models for incremental computation. Theoretical Computer Science 130(1):203–236, 1994. [Among other results, observes an easy reduction from parity prefix sums to dynamic reachability. See also Fredman and Henzinger 1998.]
- Mihai Pătraşcu. Lower bounds for dynamic connectivity. Encyclopedia of Algorithms, 463–477. Springer, 2008. [Overview of the author's two Ω(log n) cell-probe lower bound proofs.]
- Mihai Pătraşcu. Unifying the landscape of cell-probe lowerbounds. SIAM J. Computing 40(3): 827–847, 2011. [Proves several cell-prove lower bounds, including an Ω(log n/log log n) lower bound for dynamic connectivity, via reductions from lopsided set disjointness.]
- Mihai Pătraşcu* and Erik D. Demaine. Logarithmic lower bounds in the cell-probe model. SIAM J. Computing 35(4):932–963, 2006. [Proves Ω(log n) cell-probe lower bound for dynamic connectivity (by reduction from partial sums) using the “time tree” technique.]
- Mihai Pătraşcu* and Corina E. Tarniţă*. On dynamic bit-probe complexity. Theoretical Computer Science 380, 2007. [Reproves Ω(log n) cell-probe lower bound for dynamic connectivity (by reduction from partial sums) using a modification of Fredman and Saks' chronogram technique.]
- Andrew Chi-Chih Yao. Should tables be sorted? J. ACM 28(3):615–628, 1981. [Formally introduces the cell-probe model of computation. The answer is “Not if you can hash.”]
Fri Oct 1
Efficient priroty queues: Implicit d-ary heaps, Fibonacci heaps, pairing heaps, rank-pairing heaps

An implicit binary tree [Eytzinger 1590]
- Clark A. Crane*. Linear lists and priority queues as balanced binary trees. Ph.D. thesis, Computer Science Department, Stanford University, 1972. Technical Report STAN-CS-72-259, [Leftist heaps, the first priority queue to support Meld in O(log n) time.]
- Michaël Eytzinger. Thesavrvs principvm hac ætate in Evropa viventium. Kempensem, Köln, 1590. [The first use of implicit binary trees.]
- Robert W. Floyd. Algorithm 113: Treesort. Communications of the ACM 5(8):434, 1962. [An early version of heapsort, which used an array as an implicit tournament tree.]
- Robert W. Floyd. Algorithm 245: Treesort 3. Communications of the ACM 7(12):701, 1964. [The algorithm now universally known as heapsort, including a linear-time in-place algorithm for building an implicit binary heap from an unsorted array.]
- David B. Johnson. Priority queues with update and finding minimum spanning trees. Information Processing Letters 4(3):53–57, 1975. [Implicit d-ary heaps.]
- John W. J. Williams. Algorithm 232: Heapsort. Communications of the ACM 7(6):347–348, 1964. [Array-based implicit heaps, and possibly the first use of the word “heap” to mean a data structure implementing a priority queue.]

- Gerth Stølting Brodal*. Worst-case efficient priority queues. Proc. 7th ACM-SIAM Symposium on Discrete Algorithms, 52–58, 1996. [The first priority queue whose worst-case time bounds match the amortized time bounds of Fibonacci heaps.]
- Gerth Stølting Brodal, George Lagogiannis, and Robert E. Tarjan. Strict Fibonacci heaps. Proc. 44th ACM Symposium on Theory of Computing 1177--1184, 2012. [The first pointer-based priority queue whose worst-case time bounds match the amortized time bounds of Fibonacci heaps.]
- Timothy Chan. Quake heaps: A simple alternative to Fibonacci heaps. Space-Efficient Data Structures, Streams, and Algorithms: 27-32. Lecture Notes in Computer Science 8066, Springer, 2013.
- James R. Driscoll, Harold N. Gabow, Ruth Shrairman, and Robert E. Tarjan. Relaxed heaps: An alternative to Fibonacci heaps with applications to parallel computation. Commununications of the ACM 31(11):1343–1354, 1988. [Frankie say the heap property doesn't always have to be satisfied everywhere.]
- Stefan Edelkamp. Rank-relaxed weak queues: Faster than pairing and Fibonacci heaps? Technical report 54, TZI, Universität Bremen, 2009. [Answer: Only if you don't need DecreaseKey.]
- Stefan Edelkamp, Amr Elmasry, Jyrki Katajainen, and Armin Weiß. Weak heaps and friends: Recent developments. Proc. 24th International Workshop on Combinatorial Algorithms 1–6. Lecture Notes in Computer Science 8288, Springer, 2013. [A brief survey of descendants of Dutton's weak heaps.]
- Stefan Edelkamp, Amr Elmasry, and Jyrki Katajainen. The weak-heap family of priority queues in theory and praxis. Proc. 18th Computing: The Australasian Theory Symposium, 103–112, 2012.
- Amr Elmasry. The violation heap: A relaxed Fibonacci-like heap. Proc. 16th Annual International Conference on Computing and Combinatorics 479–488, 2010.
- Michael L. Fredman and Robert E. Tarjan. Fibonacci heaps and their uses in improved network optimization algorithms. J. Association for Computing Machinery 34(3):596–615, 1987. [The original Fibonacci heap paper.]
- Bernard Haeupler*, Siddhartha Sen*, and Robert E. Tarjan. Rank-pairing heaps. SIAM J. Computing 40(6):1463–1485, 2011. [Lazy binomial queues with pairing by rank and rank-adjustment. Following the Red Herring Principle, rank-pairing heaps are not actually a variant of pairing heaps; by analogy, Fibonacci heaps should be called “degree-pairing heaps”.]
- Peter Høyer. A general technique for implementation of efficient priority queues. Proc. 3rd Israel Symposium on Theory of Computer Systems, 57–66, 1995. [Just what it says on the tin. Red-black heaps and mergeable double-ended priority queues.]
- Haim Kaplan and Robert E. Tarjan. Thin heaps, thick heaps. ACM Transactions on Algorithms 4(1), Article 3, 2008.
-
Daniel H. Larkin*, Siddhartha Sen*, Robert E. Tarjan. A back-to-basics empirical study of priority queues. Proc. 16th Workshop on Algorithm Engineering and Experiments, 61–72, 2014. arXiv:1403.0252. Code available at https://
code.google.com/ . [Implicit d-ary heaps and pairing heaps are the best choices in practice. Binomial and Fibonacci heaps are next best. Everything else sucks.]p/ priority-queue-testing/ - Daniel D. Sleator* and Robert E. Tarjan. Self-adjusting heaps. SIAM J. Computing 15(1):52–69, 1986. [Skew heaps, otherwise known as self-adjusting leftist heaps.]
- Tadao Takaoka. Theory of 2-3 heaps. Discrete Applied Mathematics 126(1):115–128, 2003.
- Tadao Takaoka. Theory of trinomial heaps. Proc. 6th Annual Int. Conf. Computing and Combinatorics, 362-372. Lecture Notes in Computer Science 1858, 2000.
- Jean Vuillemin. A data structure for manipulating priority queues. Communications of the ACM 21, 309–314, 1978. [Binomial “queues”.]

- Ronald D. Dutton. Weak-heap sort. BIT 33(3):372–381, 1993. [Weak heaps, a clever implicit variant of binomial queues. Roughly a factor of 2 faster than standard binary heaps, at the cost of one extra bit per item.]
- Amr Elmasry. Pairing heaps with O(log log n) decrease cost. Proc. 20th Annual ACM-SIAM Symposium on Discrete Algorithms, 471–476, 2000. [A variant of pairing heaps that is not covered by Fredman's lower bound.]
- Amr Elmasry. Pairing heaps, scrambled pairing and square-root trees. International J. Computer Mathematics 87(14):3096–3110, 2010. [A pairing heap with a bad pairing strategy can require Ω(√n) amortized time per operation.]
- Michael L. Fredman. On the efficiency of pairing heaps and related data structures. J. ACM 46(4):473–501, 1999. [Pairing heaps require Ω(log log n) amortized time for DecreaseKey.]
- Michael L. Fredman, Robert Sedgewick, Daniel D. Sleator*, and Robert E. Tarjan. The pairing heap: A new form of self-adjusting heap. Algorithmica 1(1):111–129, 1986.
- John Iacono. Improved upper bounds for pairing heaps. Proc. 7th Scandinavian Workshop on Algorithm Theory, 63--77. Lecture Notes in Computer Science 1851, Springer, 2000. arXiv:1110.4428.
-
Daniel H. Larkin*, Siddhartha Sen*, Robert E. Tarjan. A back-to-basics empirical study of priority queues. Proc. 16th Workshop on Algorithm Engineering and Experiments, 61–72, 2014. arXiv:1403.0252. Code available at https://
code.google.com/ . [Implicit d-ary heaps and pairing heaps are the best choices in practice. Binomial and Fibonacci heaps are next best. Everything else sucks.]p/ priority-queue-testing/ - Seth Pettie. Towards a final analysis of pairing heaps. Proc. 46th Annual IEEE Symposium on Foundations of Computer Science, 174–183, 2005. [O(22 sqrt{log log n}) amortized time for Insert, Meld, and DecreaseKey. Not universally believed.]