In 1977, Victor Klee asked the following question. Given a collection of intervals on the
real line, how quickly can we compute the length of their union? Klee observed that an
O(n log n) solution follows easily from your favorite sorting algorithm, and
Michael Fredman and Bruce Weide showed that this is optimal in the linear decision tree
model.
|
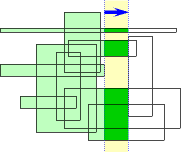
One step of Bentley's sweep-line algorithm.
The darker green area is added to the running total.
|
Later the same year, Jon Bentley considered a (the?) natural generalization to two
dimensions: Given a collection of axis-aligned rectangular boxes, how quickly can we
compute the area of their union? Bentley described an optimal O(n log
n)-time solution that uses a dynamic version of the
one-dimensional problem. Bentley's algorithm sweeps a vertical line from left to
right across the rectangles, maintaining the intersection of the rectangles and the sweep
line -- a collection of intervals -- in a segment tree. Whenever the sweep line hits a
vertical edge of a rectangle, the segment tree is updated, along with a running total of
the swept area. Each update happens in O(log n) time. Perhaps the
most important feature of Bentley's algorithm is that it computes the area without
explicitly constructing the union, which can easily have quadratic complexity.
Bentley's sweepline strategy transforms a single d-dimensional measure problem into
n (d-1)-dimensional measure problems, so it immediately yields an
algorithm with running time O(n2 log n) when
d=3. However, this algorithm does not exploit the "coherence" between successive
lower-dimensional problems. In 1985, Jan van Leeuwen and Derek Wood improved
Bentley's algorithm by a logarithmic factor using dynamic quadtrees, which allow a single
2-dimensional box to be inserted or deleted in O(n) time.
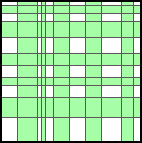
A trellis. The green area can be computed
in linear time once the rectangles are sorted.
|
|
Finally, in 1991, Mark Overmars and Chee Yap proposed a dynamic data structure reminiscent
of kd-trees that handles insertions or deletions of 2-dimensional boxes in
O(sqrt(n) log n) time. Thus, the overall running time of their
algorithm is O(n3/2 log n), which is the fastest
known. Overmars and Yap's data structure partitions the plane into rectangular cells, so
that within each cell, the boundaries of the input boxes form a grid, or trellis.
The regular structure of a trellis allows its union to be computed and maintained
efficiently.
Unfortunately, the best known lower bound for this problem, even in higher dimensions, is
only Omega(n log n). Is there an O(n polylog
n)-time algorithm for Klee's measure problem in 3 (or more) dimensions?
Alternately, is there an Omega(n3/2) lower bound? I suspect that the
answer to the second question is yes, although I don't have a clue what the right model of
computation should be!
In dimensions d>3, Bentley's algorithm runs in O(nd-1
log n) time, van Leeuwen and Wood's algorithm in
O(nd-1) time, and Overmars and Yap's algorithm in
O(nd/2 log n) time, which is the fastest
known. Is there a subquadratic algorithm, or a quadratic lower bound, for Klee's
measure problem in 4 (or more) dimensions? It seems plausible (at least to me) that
something similar to a dynamic (d-1)-dimensional kd-tree can be used to get
a subquadratic running time in any dimension.
All of these algorithms can be adapted to compute other measures of the union, such as
surface area or combinatorial complexity, instead of volume. They can also be used to
compute the depth of an arrangement of boxes, which is the maximum number of
boxes that contain a common point.
I think a near-linear-time algorithm for the general case is too much to hope for, but
there are a few special cases that may have more efficient solutions. Can we solve
Klee's measure problem more quickly if all the boxes are fat, that is, if the
longest edge of each box is only a constant factor longer than its shortest edge? If the
boxes are also scale bounded, that is, the largest box is only a constant factor
bigger than the smallest box? To answer the first question, it suffices to look at the
case where every box is a hypercube, and for the second question, where every hypercube
has the same size. The complexity of the union of axis-aligned hypercubes is only
O(nceiling{d/2}), or O(nfloor{d/2}) if all the
hypercubes are the same size. This means that we can (almost certainly) construct the
union of unit hypercubes, and thus compute its volume, in O(nfloor{d/2}
polylog n) time using a randomized incremental construction, improving
Overmars and Yap's algorithm by roughly O(sqrt{n}) whenever the dimension is odd.
Unfortunately, such an algorithm could not be used to compute the depth of the hypercube
arrangement more quickly.
Computing the depth of an arrangement of unit hypercubes has the following useful and
equivalent interpretation: Given a set of points, find the largest subset that fits inside
a unit hypercube. David Eppstein and I used Overmars and
Yap's algorithm for this special case as a subroutine to find, given n points in
d-space, the smallest hypercube containing k of them, in
O(nd/2 log2n) time. Recent work of Timothy
Chan removes the extra logarithmic factor from this time bound, and techniques of Amitava
Datta and others reduce the time bound further, to O(n log n +
nkd/2-1 log k).
The closely related problem of computing the area of the union of triangles in
the plane, or the depth of their arrangement, has an O(n2)-time
solution that can be summed up in three words--Construct the arrangement!
Although the best lower bound known is only Omega(n log n), the
triangle-union problem is 3SUM-hard, so a subquadratic solution
is highly unlikely. Given n circles in the plane, the area of their union
can be computed in O(n log n) time using power diagrams, but
computing the depth of their arrangement is again 3SUM-hard.
 Open Problems -
Jeff Erickson
(jeffe@cs.uiuc.edu)
31 Jul 1998
Open Problems -
Jeff Erickson
(jeffe@cs.uiuc.edu)
31 Jul 1998